LottieGPT: Tokenizing Vector Animation for Autoregressive Generation
Junhao Chen, Kejun Gao, Yuehan Cui, Mingze Sun, Mingjin Chen, Shaohui Wang, Xiaoxiao Long, Fei Ma, Qi Tian, Ruqi Huang, Hao Zhao
Abstract: Despite rapid progress in video generation, existing
models are incapable of producing vector animation, a
dominant and highly expressive form of multimedia on the
Internet. Vector animations offer resolution-independence,
compactness, semantic structure, and editable parametric
motion representations, yet current generative models operate exclusively in raster space and thus cannot synthesize them. Meanwhile, recent advances in large multimodal models demonstrate strong capabilities in generating structured data such as slides [26], 3D meshes [73], LEGO
sequences [62], and indoor layouts [56], suggesting that
native vector animation generation may be achievable. In
this work, we present the first framework for tokenizing and
autoregressively generating vector animations. We adopt
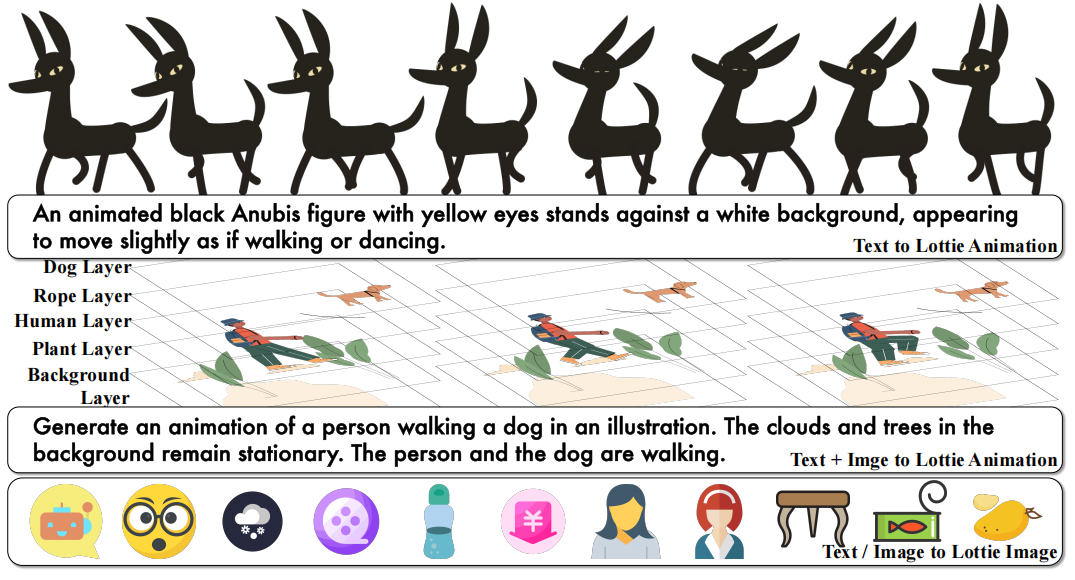
Lottie, a widely deployed JSON-based animation standard,
and design a tailored Lottie Tokenizer that encodes layered geometric primitives, transforms, and keyframe-based
motion into a compact and semantically aligned token sequence. To support large-scale training, we also construct
LottieAnimation-660K, the largest and most diverse vector animation dataset to date, consisting of 660k real-world
Lottie animation and 15M static Lottie image files curated
from broad Internet sources. Building upon these components, we finetune Qwen-VL to create LottieGPT, a native multimodal model capable of generating coherent, editable vector animations directly from natural language or
visual prompts. Experiments show that our tokenizer dramatically reduces sequence length while preserving structural fidelity, enabling effective autoregressive learning of
dynamic vector content. LottieGPT exhibits strong generalization across diverse animation styles and outperforms
previous state-of-the-art models on SVG generation (a special case of single-frame vector animation).
Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2026