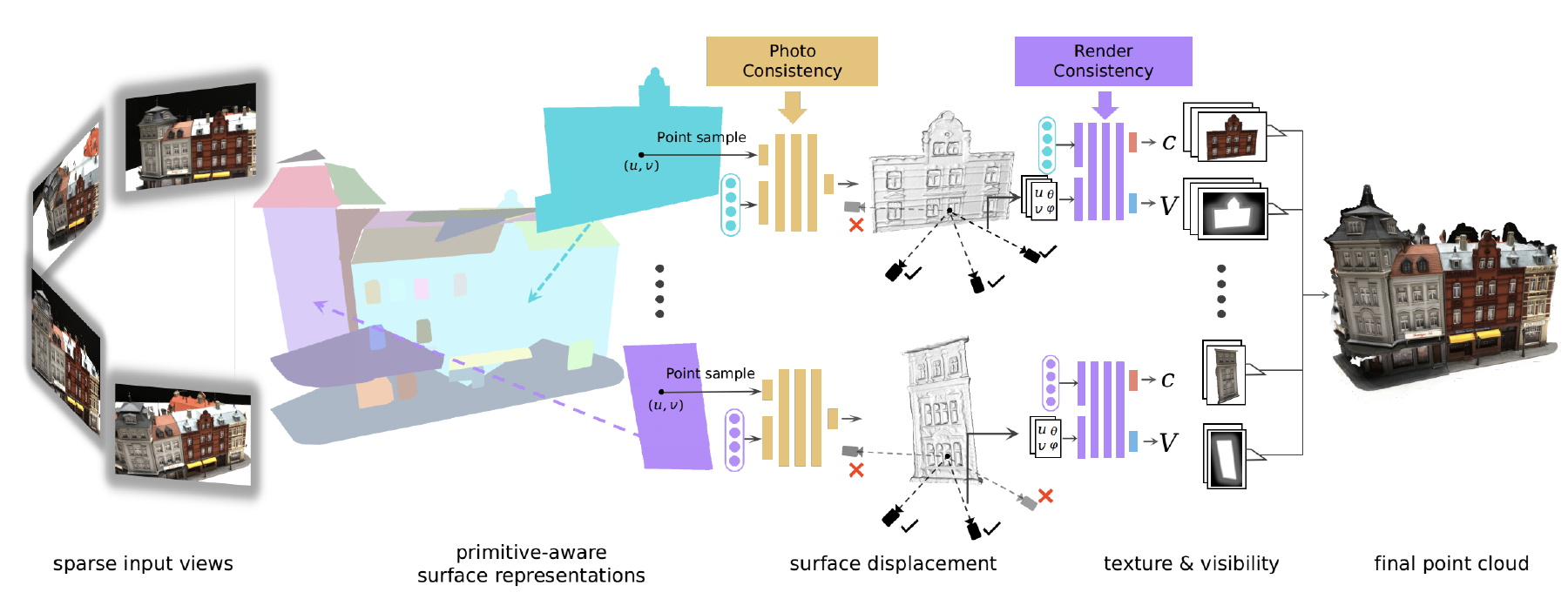
GS-Playground: A High-Throughput Photorealistic Simulator for Vision-Informed Robot Learning
Yufei Jia, Heng Zhang, Ziheng Zhang, Junzhe Wu, Mingrui Yu, Zifan Wang, Dixuan Jiang, Zheng Li, Chenyu Cao, Zhuoyuan Yu, Xun Yang, Haizhou Ge, Yuchi Zhang, Jiayuan Zhang, Zhenbiao Huang, Tianle Liu, Shenyu Chen, Jiacheng Wang, Bin Xie, Xuran Yao, Xiwa Deng, Guangyu Wang, Jinzhi Zhang, Lei Hao, Zhixing Chen, Yuxiang Chen, Anqi Wang, Hongyun Tian, Yiyi Yan, Zhanxiang Cao, Yizhou Jiang, Hanyang Shao, Yue Li, Lu Shi, Wei Sui, Hanqing Cui, Yusen Qin, Ruqi Huang, Bokui Chen, Lei Han, Tiancai Wang, Guyue Zhou
Abstract: Embodied AI research is undergoing a shift toward vision-centric perceptual paradigms. While massively parallel
simulators have catalyzed breakthroughs in proprioception-based
locomotion, their potential remains largely untapped for visioninformed tasks due to the prohibitive computational overhead of
large-scale photorealistic rendering. Furthermore, the creation
of simulation-ready 3D assets heavily relies on labor-intensive
manual modeling, while the significant sim-to-real physical gap
hinders the transfer of contact-rich manipulation policies. To
address these bottlenecks, we propose GS-Playground, a multimodal simulation framework for high-throughput, photorealistic
robot learning in interactive rigid-body settings. We develop
MotrixSim, a novel high-performance parallel physics engine,
specifically designed to integrate with a batch 3D Gaussian
Splatting (3DGS) rendering pipeline to ensure high-fidelity
synchronization. Our system achieves an aggregate rendering
throughput of 104 FPS across 2048 environments at 640 × 480
resolution, significantly lowering the barrier for large-scale visual
RL. Additionally, we introduce a Real2Sim workflow that reconstructs photorealistic and memory-efficient simulation-ready
environments, reducing the manual effort required to create
complex scenes for robot interaction. Extensive experiments
on locomotion, navigation, and manipulation demonstrate that
GS-Playground enables high-throughput photorealistic RL
and robust Sim2Real transfer for interactive rigid-body robot learning.
Robotics: Science and Systems (RSS), 2026